리눅스 컨테이너(LXC) 기술이 등장한 이후로 전가상화(full virtualization) 및 반가상화(para virtualization)의 시대가 저물어버렸습니다. Docker는 LXC에서 사용하는 리눅스 커널 컨테이너 기술을 이용해 만든 컨테이터 관리 유틸리티로 마이크로서비스 전환은 물론 DevOps, 테스팅 등 다양한 분야에서 많은 사랑을 받고 있어 리눅스 컨테이너 구현체의 사실상(de-facto) 업계 표준이 되었습니다.
Docker에 대한 사용 방법은 가장 빨리 만나는 Docker를 읽어보시는 것을 추천드립니다. 이 글은 Docker의 핵심 기술로 쓰이는 리눅스 커널의 cgroups와 namespaces를 알아보는 글입니다.
Container는 가상머신이다?
Container는 hypervisor와 완전히 다릅니다. 궁극적으로는 hypervisor와 유사한 형태의 "가상화"를 목표로 하고 있지만 hypervisor는 OS 및 커널이 통째로 가상화되는 반면에 container는 간단히 보면 filesystem의 가상화만을 이루고 있습니다. container는 호스트 PC의 커널을 공유하고 따라서 init(1) 등의 프로세스가 떠있을 필요가 없으며, 따라서 가상화 프로그램과는 다르게 적은 메모리 사용량, 적은 overhead를 보입니다.
Container vs VM의 성능 차이
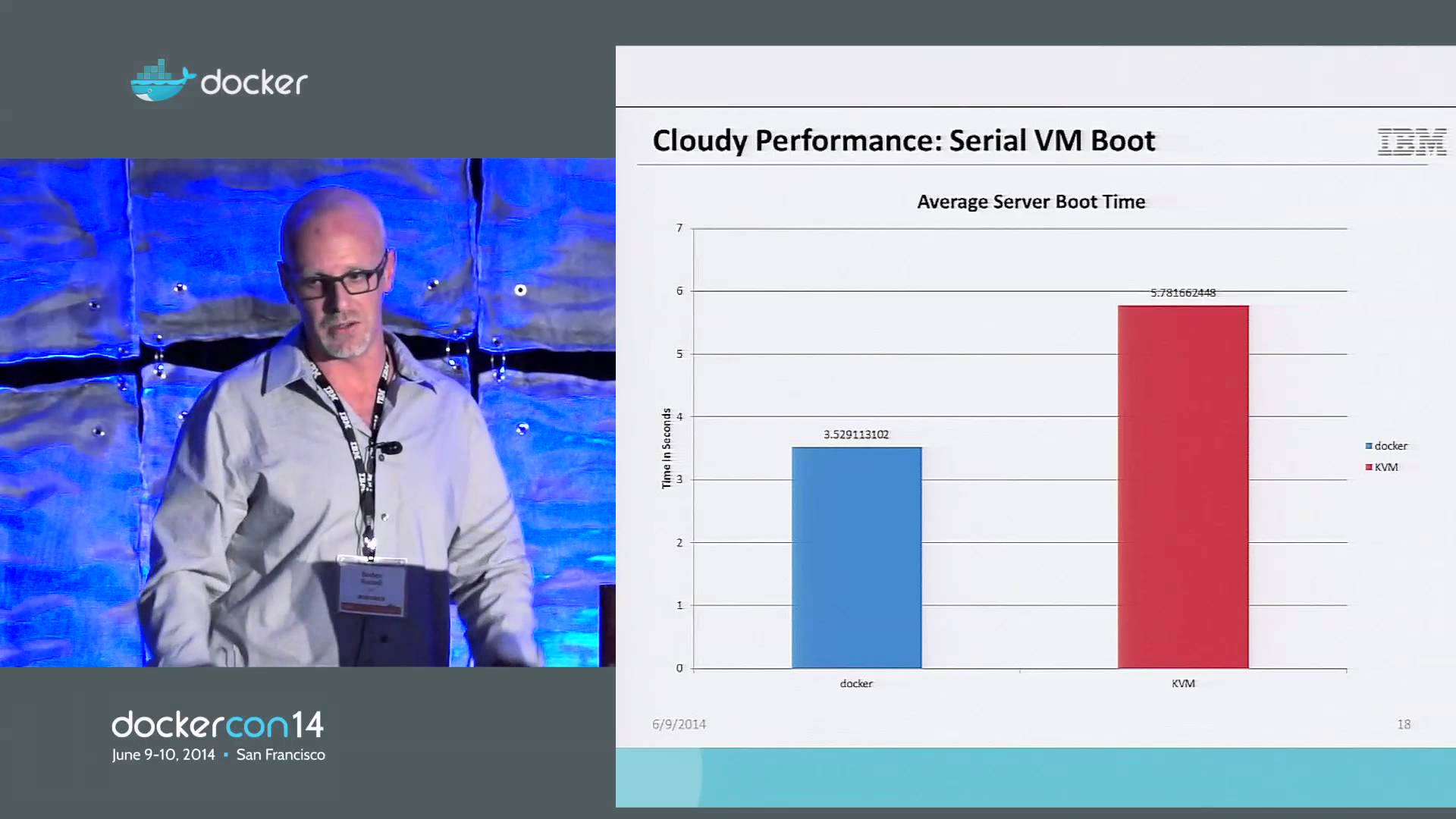
실제 하드웨어인 것처럼 에뮬레이션(emulation)을 하는 VM과 달리 container는 호스트 PC의 자원을 격리(isolation)된 상태로 그대로 활용하기 때문에 VM에 비해 성능 저하가 눈에 띄게 적습니다.
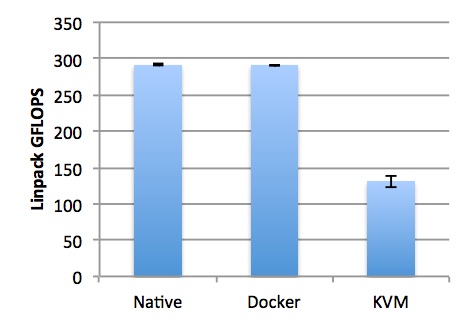
실제 온라인상에 돌아다니는 많은 벤치마크 자료를 통해 이를 입증할 수 있으며 container 사용으로 인한 성능 손실은 native에 비해 1% 수준에 불과합니다. 이는 가상화(virtualization)를 하지 않는 부분에서 오는 container의 가장 큰 장점입니다.
컨테이너 기술
namespaces
VM에서는 각 게스트 머신별로 독립적인 공간을 제공하고 서로가 충돌하지 않도록 하는 기능을 갖고 있습니다. 리눅스에서는 이와 동일한 역할을 하는 namespaces 기능을 커널에 내장하고 있습니다. 글을 쓰는 시점을 기준으로 현재 리눅스 커널에서는 다음 6가지 namespace를 지원하고 있습니다:
- mnt (파일시스템 마운트): 호스트 파일시스템에 구애받지 않고 독립적으로 파일시스템을 마운트하거나 언마운트 가능
- pid (프로세스): 독립적인 프로세스 공간을 할당
- net (네트워크): namespace간에 network 충돌 방지 (중복 포트 바인딩 등)
- ipc (SystemV IPC): 프로세스간의 독립적인 통신통로 할당
- uts (hostname): 독립적인 hostname 할당
- user (UID): 독립적인 사용자 할당
namespaces를 지원하는 리눅스 커널을 사용하고 있다면 다음 명령어를 통해 바로 namespace를 만들어 실행할 수 있습니다, 여기서는 간단하게 PID namespace를 띄워봅시다:
$ sudo unshare --fork --pid --mount-proc bash
자 이제 독립적인 공간이 할당됐을까요?
root@ssut:~# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 4.0 0.0 17656 6924 pts/9 S 22:06 0:00 bash
root 2 0.0 0.0 30408 1504 pts/9 R+ 22:06 0:00 ps aux
네, 잘 작동하고 있습니다. PID namespace에 실행한 bash가 PID 1로 할당되어 있고(일반적으로 init(커널)이 PID 1) 바로 다음으로 실행한 "ps aux" 명령어가 PID 2를 배정받았습니다.
이 PID namespace 안에서 실행한 프로세스를 밖에서도 볼 수 있을까요? 한 번 확인해보죠.
root@ssut:~# top
...
ssut@ssut:~$ ps aux | grep top
root 9710 0.0 0.0 34716 2988 pts/9 S+ 22:29 0:00 top
우리가 가둬서 실행했던 PID namespace 밖의 공간(regular namespace)에서도 프로세스를 확인할 수 있다는 것을 알았습니다. 즉, namespaces 기능은 같은 공간을 공유하되 조금 더 제한된 공간을 할당해주는 것이라 볼 수 있습니다.
namespace를 통해 독립적인 공간을 할당한 후에는 nsenter라는 명령어를 통해 이미 돌아가고 있는 namespace 공간에 접근할 수 있습니다. 이 명령어는 명령어 이름 자체가 암시하고 있듯 namespace enter의 약자입니다. Docker에서는 docker exec가 이와 비슷한 역할을 하고 있습니다. (단 nsenter의 경우 docker exec와는 다르게 cgroups에 들어가지 않기 때문에 리소스 제한의 영향을 받지 않습니다)
cgroups (Control Groups)
cgroups(Control Groups)는 자원(resources)에 대한 제어를 가능하게 해주는 리눅스 커널의 기능입니다. cgroups는 다음 리소스를 제어할 수 있습니다:
- 메모리
- CPU
- I/O
- 네트워크
- device 노드(
/dev/)
실행중인 프로그램의 메모리를 제한해볼까요? 일단 "ssut" 유저가 소유하고 메모리를 제어할 testgrp를 생성해봅시다.
ssut@ssut:~$ sudo cgcreate -a ssut -g memory:testgrp
ssut@ssut:~$ ls -alh /sys/fs/cgroup/memory/testgrp
합계 0
drwxr-xr-x 2 ssut root 0 8월 8 23:19 .
dr-xr-xr-x 8 root root 0 7월 7 15:30 ..
-rw-r--r-- 1 ssut root 0 8월 8 23:19 cgroup.clone_children
--w--w--w- 1 ssut root 0 8월 8 23:19 cgroup.event_control
-rw-r--r-- 1 ssut root 0 8월 8 23:19 cgroup.procs
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.failcnt
--w------- 1 ssut root 0 8월 8 23:19 memory.force_empty
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.kmem.failcnt
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.kmem.limit_in_bytes
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.kmem.max_usage_in_bytes
-r--r--r-- 1 ssut root 0 8월 8 23:19 memory.kmem.slabinfo
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.kmem.tcp.failcnt
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.kmem.tcp.limit_in_bytes
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.kmem.tcp.max_usage_in_bytes
-r--r--r-- 1 ssut root 0 8월 8 23:19 memory.kmem.tcp.usage_in_bytes
-r--r--r-- 1 ssut root 0 8월 8 23:19 memory.kmem.usage_in_bytes
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.limit_in_bytes
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.max_usage_in_bytes
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.move_charge_at_immigrate
-r--r--r-- 1 ssut root 0 8월 8 23:19 memory.numa_stat
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.oom_control
---------- 1 ssut root 0 8월 8 23:19 memory.pressure_level
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.soft_limit_in_bytes
-r--r--r-- 1 ssut root 0 8월 8 23:19 memory.stat
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.swappiness
-r--r--r-- 1 ssut root 0 8월 8 23:19 memory.usage_in_bytes
-rw-r--r-- 1 ssut root 0 8월 8 23:19 memory.use_hierarchy
-rw-r--r-- 1 ssut root 0 8월 8 23:19 notify_on_release
-rw-r--r-- 1 root root 0 8월 8 23:19 tasks
/sys/fs/cgroup/*/groupname 경로에 있는 파일을 통해 그룹의 여러 옵션을 변경할 수 있습니다. 최대 메모리 사용량을 2MB로 제한해볼까요? memory.kmem.limit_in_bytes 파일을 다음 명령어로 수정해줍시다:
ssut@ssut:~$ echo 2000000 > /sys/fs/cgroup/memory/testgrp/memory.kmem.limit_in_bytes
이제 우리가 생성한 cgroup에서 bash 셸을 실행시켜 메모리 제한이 잘 먹히나 확인해봅시다:
ssut@ssut:~$ sudo cgexec -g memory:testgrp bash
root@ssut:~# top
top: error while loading shared libraries: libgpg-error.so.0: failed to map segment from shared object
메모리 제한이 잘 되는 것을 확인할 수 있습니다. 이를 통해 container에서는 VM에서와 동일하게 리소스 할당량을 제한할 수 있게 됩니다.
lxc, libcontainer, runc...
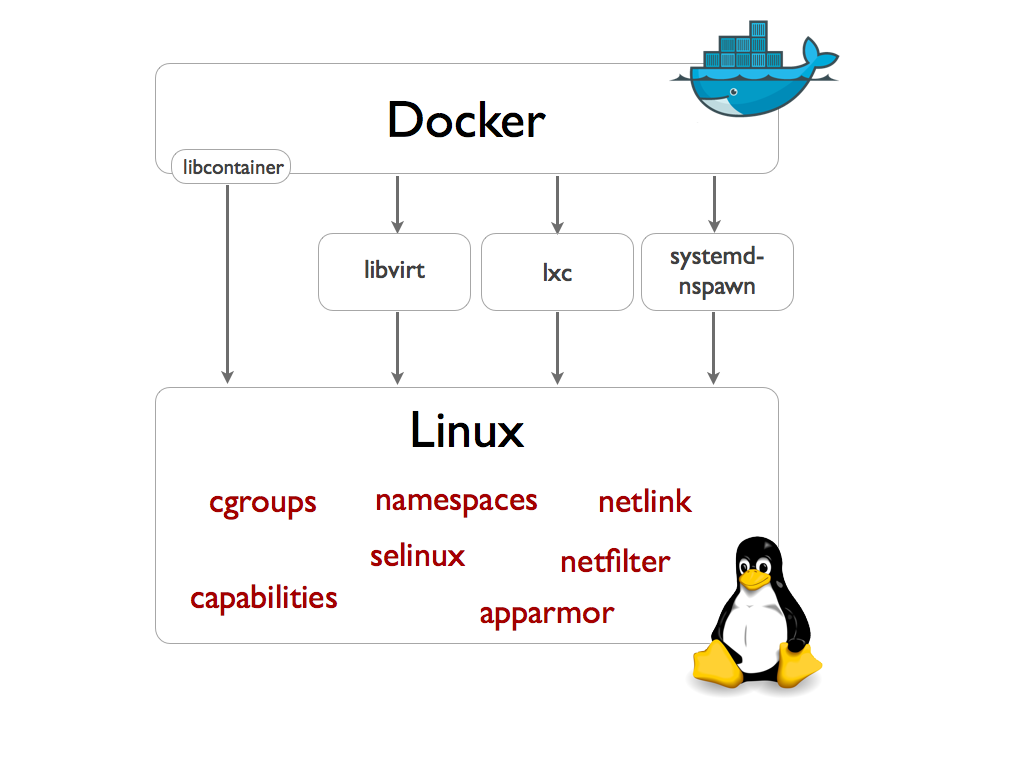
LXC, LibContainer, runC 등은 위에서 설명한 cgroups, namespaces를 표준으로 정의해둔 OCI(Open Container Initative) 스펙을 구현한 컨테이너 기술의 구현체입니다. LXC는 캐노니컬(Canonical)이 지원하고 있는 리눅스 컨테이너 프로젝트로 Docker의 경우 1.8 이전 버전까지 LXC를 이용해 구현해서 사용했었습니다. 이후에 Docker는 libcontainer -> runC (libcontainer의 리팩토링 구현체)로 자체 구현체를 갖게 되었습니다.
Docker
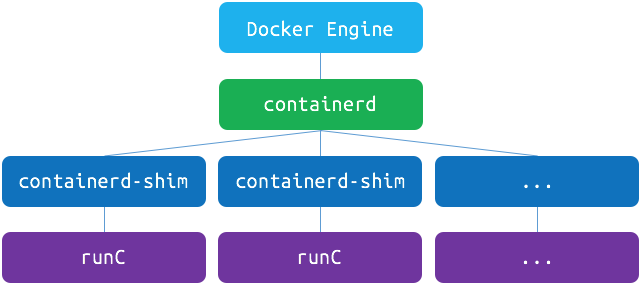
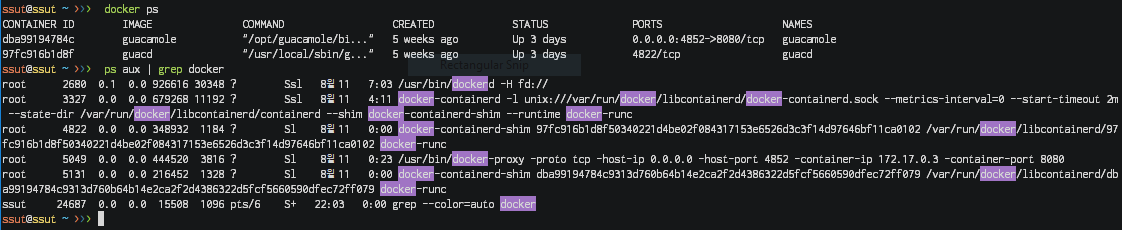
docker는 1.11버전부터 실제로 위와 같은 구조로 작동하고 있습니다. containerd는 OCI 구현체(주로 runC)를 이용해 container를 관리해주는 daemon입니다. Docker engine 자체는 이미지, 네트워크, 디스크 등의 관리 역할을 하고 있으며, 여기서 Docker engine과 containerd 각각이 완전히 분리된 덕분에 Docker engine 버전을 올릴 때 Docker engine을 재시작해도 container의 재시작 없이 사용할 수 있게 됩니다.
위와 같이 docker에서 각각의 역할이 분리됨에 따라 docker는 4개의 독립적인 프로세스로 작동하고 있습니다. ps aux | grep docker 명령으로 확인해보면 docker, docker-containerd, docker-containerd-shim, docker-runc 4개의 프로세스가 돌아가고 있는 것을 확인할 수 있습니다.