Google이 Go 언어를 만들어낸 이후 많은 시스템 관리용 유틸리티, 서버가 Go로 짜여지기 시작했고 매 업데이트마다 엄청난 성능 향상과 발전으로 이제 어디서든 Go 언어로 짜여진 프로그램을 쉽게 만날 수 있게 되었습니다. 특히 이전에 올렸던 HTTP Server Benchmark 글에서 보여준 Go의 성능은 많은 이들에게 감명을 줄 수 있는 수준이라 생각됩니다. 이러한 Go의 놀라운 성능 뒤에는 어떤 비결이 숨겨져 있을까요? 단순 컴파일 언어라서, 최적화가 잘 되어있어서 Go가 빠른 것일까요? Goroutines에 대해 알아봅시다.
프로세서 성능의 한계
무어의 법칙은 깨진지 꽤 오래됐습니다. 2004년 3GHz CPU가 세상에 선보인 이후로 2017년 공개되고 있는 CPU의 클럭은 약 4GHz 수준입니다. 아 하이엔드만 그렇고 일반적으로 2~3GHz 클럭을 가진 CPU를 아직도 사용하고 있죠.
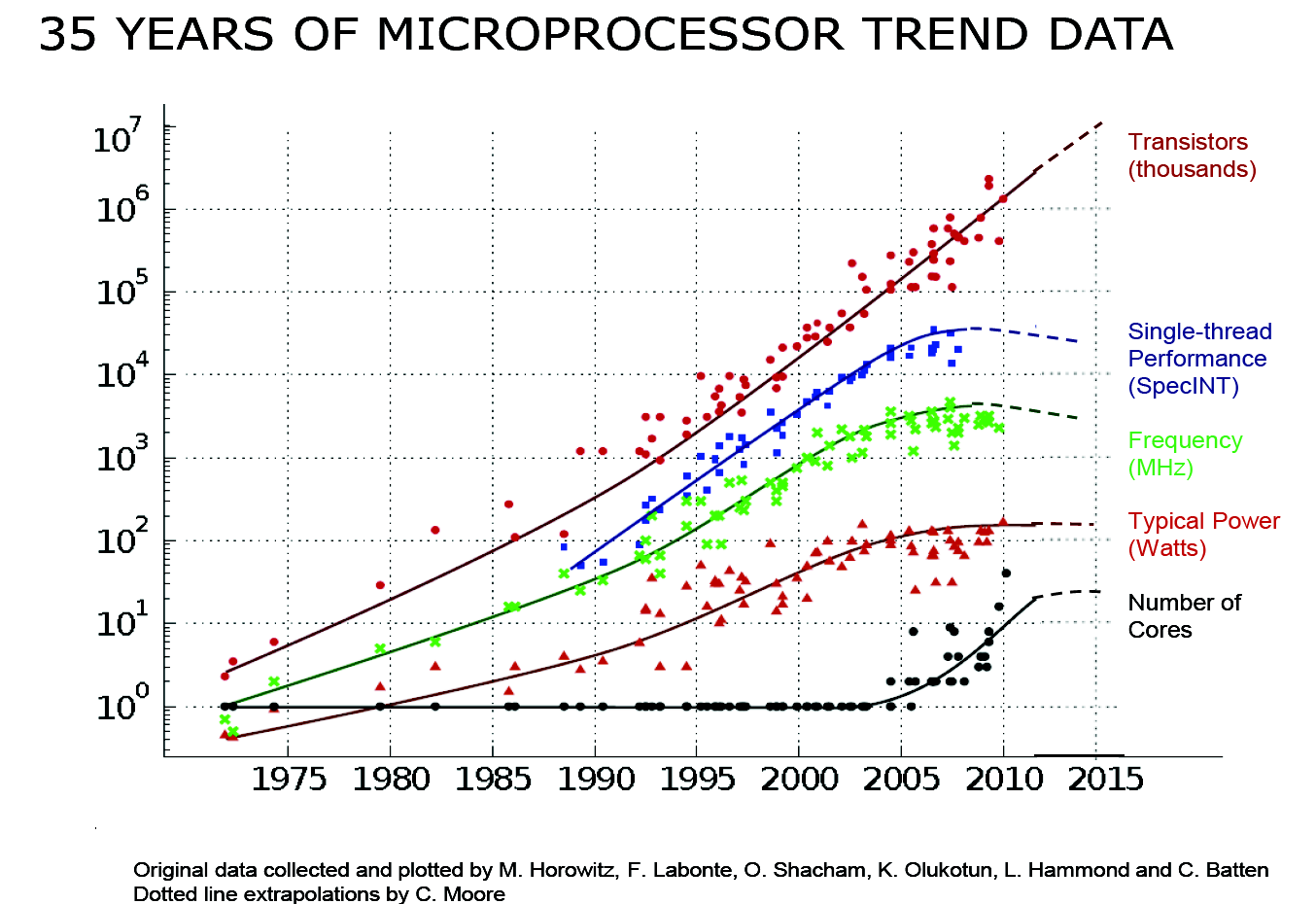
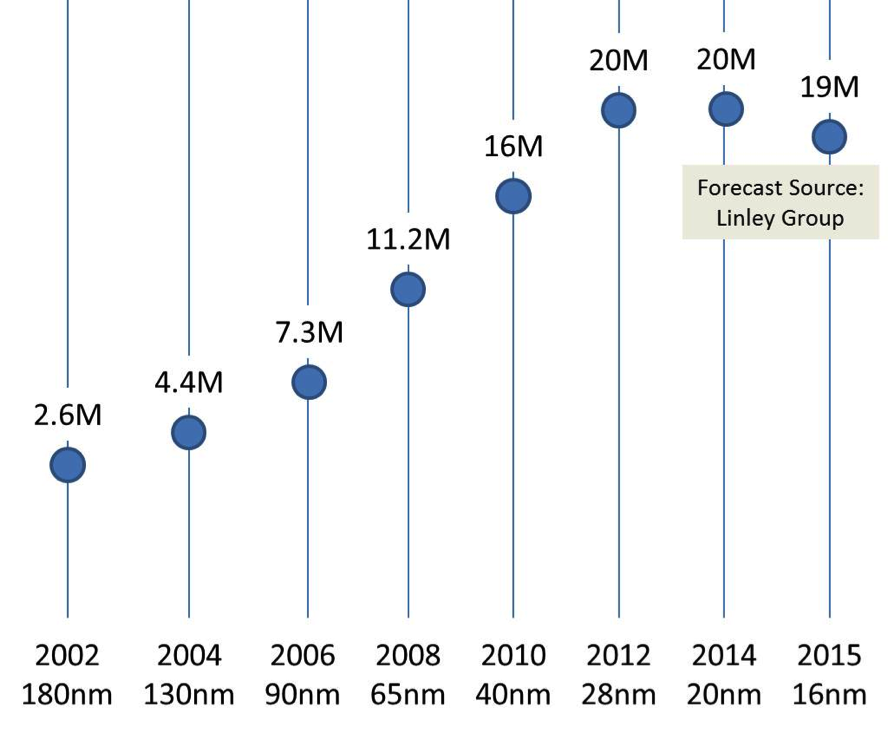
위 자료로 볼 수 있듯 클럭 속도는 떨어지고 있습니다. 게다가 가격 대비 트랜지스터 수 또한 떨어지기 시작한 상황입니다.하지만 과거와 비교해볼 때 CPU의 성능은 떨어지지 않았습니다. 무엇이 이를 가능하게 해줬을까요? 여기에는 하이퍼스레딩(hyperthreading), 멀티코어(multicore), 캐시(cache) 기술이 큰 도움이 되었습니다.

캐시는 물리적인 한계를 갖고 있습니다. 캐시가 크면 클수록 그 속도는 더 느려진다는 부분입니다. 현대의 CPU는 캐시와 코어간의 레이턴시를 낮추기 위해 칩 내부에 L1, L2, 그리고 L3 캐시까지 탑재하고 있습니다. 빛의 속도가 한정되어 있듯 거리는 (nm단위라 하더라도)속도를 의미합니다. 캐시는 RAM보다 훨씬 빠르지만 그 속도에는 결국 제한이 존재합니다.
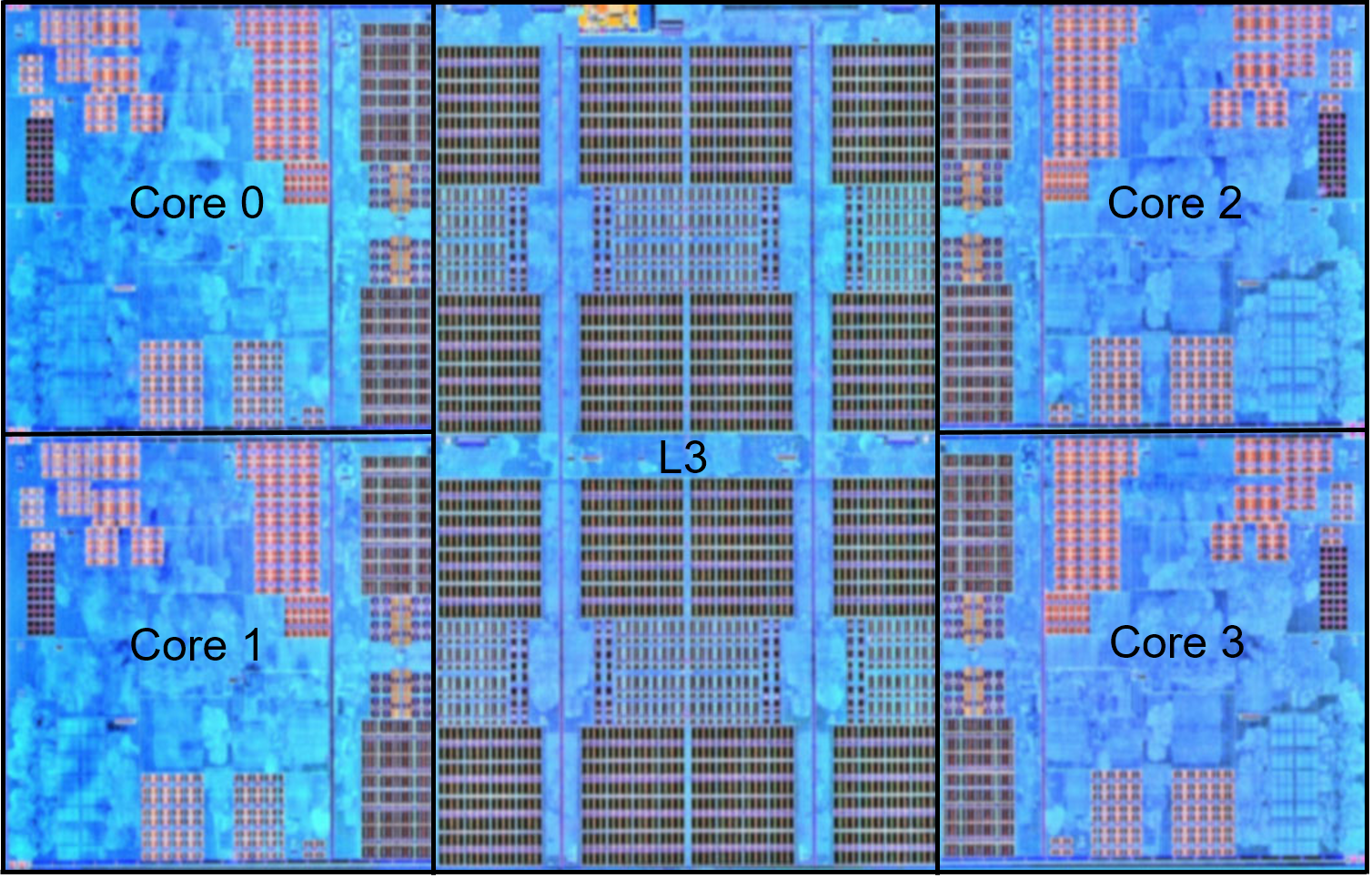
지난 몇 년간 CPU 시장(특히 Workstation/Server 시장)은 더 많은 CPU 코어를 추가하는 방식으로 성장해왔습니다. 2005년, 인텔이 본격적으로 멀티코어를 가진 Core 프로세서를 내놓기 시작하면서 높이는 데 한계가 있었던 클럭 상승폭이 주춤하기 시작했고 싱글코어 성능은 10년 단위로 봐도 큰 향상이 없었지만 멀티코어 성능은 매우 큰 폭으로 가파르게 상승하기 시작했습니다. 하지만 많은 코어 수에도 불구하고 수많은 소프트웨어가 이를 제대로 활용하지 못하는 사태가 벌어지기 시작했고(실제 2017년 Ryzen 7 프로세서 출시 이후 CPU 시장이 크게 뒤바뀌는듯 했으나 Adobe 제품군에서 4C8T인 Intel i7-7700K의 성능이 6C12T의 Ryzen 7 1700X를 가볍게 뛰어넘는 등 이는 현재진행형으로 이어지고 있습니다) 이는 결국 CPU 코어를 활용하기 위해 CPU 코어를 가상화(ESXi 등)해서 사용하는 등 비효율적인 멀티코어 활용 방법을 보편화시켰습니다.
멀티프로세싱
싱글코어의 성능을 높이는 데에는 한계가 분명히 존재하기 때문에 결국에는 소프트웨어 개발자가 나서서 멀티코어를 제대로 지원할 수 있는 소프트웨어를 만들어내야 합니다. 많은 프로그래밍 언어들은 90년대에 처음 등장했고 싱글 스레드를 사용하는 것이 당연했습니다. 멀티스레딩 또한 가능하긴 했지만 복잡하고 구현이 어려우며 값비싼 런타임 비용 때문에 쉽게 개발자가 접근할 수 없었습니다. Java에서의 스레드를 예로 들어봅시다. Java 스레드는 시작과 동시에 1MB의 스택 공간을 요구로 하고 스레드와 스레드 사이의 보호 공간(guard page)까지 필요로 합니다. 게다가 더 많은 스레드를 생성해낼 수록 heap 공간이 더 적어지는 문제점이 존재합니다.
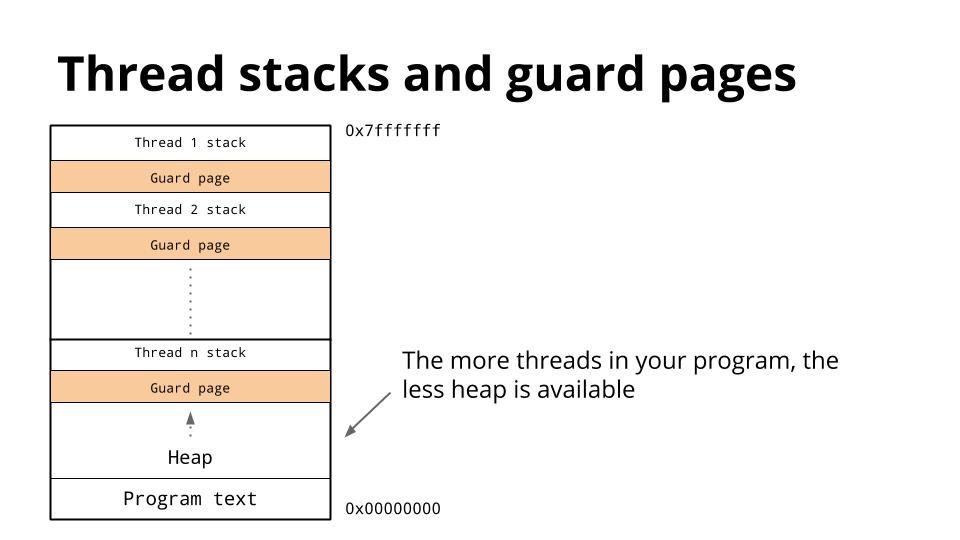
이 문제를 풀어서 해석해보면 웹 서버를 만든다고 했을 때 요청 당 1개의 스레드를 만들게 되면 결국 우리는 OutOfMemoryError를 만나게 되거나, 메모리 공간을 넘어 프로그램이 가상 메모리에 페이징되면서 전체적인 성능 저하를 겪게 됩니다. 즉 스레드 자체는 프로그램의 성능을 높이는 데에 분명한 도움을 주기는 하지만 멀티프로세싱의 해답이라 보기는 어렵다는 것입니다.
싱글 스레드를 사용하는 Nodejs, Ruby, Python 등의 잘 알려진 여러 스크립트 언어에는 위와 같은 문제가 분명히 존재하고(위 문제는 Java에만 국한되는 것이 아닌 OS의 스레드를 사용하는 모든 프로그래밍 언어가 포함됩니다) 이를 해결하기 위해 OS 프로세서당 1개의 프로세스를 띄우고 로드밸런싱(LB)을 구성하는 오래됐지만 안정적인 방법을 꽤 오래 전부터 사용해왔습니다.
Goroutines in Go
Go의 동시성 모델인 고루틴(Goroutines)은 기존의 낡은 방식에서 벗어나 새로운 방식의 멀티프로세싱을 제공합니다. 한 프로세스로 모든 코어를 활용하면서 적은 메모리를 사용하는 방식 말이죠. 이에 대한 글(+번역글)은 수도없이 많이 나와있으니 해당 글들을 찾아보시기 바랍니다. (고루틴은 어떻게 동작하는가)
고루틴은 M:N 스레드 모델(LWP)을 사용하고 있습니다. 따라서 기존의 스레드/스레드 풀 방식보다 훨씬 가볍고 빠른 특성을 지니고 있습니다.
스레드(Threads)의 종류
스레드는 다음과 같이 분류할 수 있습니다:
N:1: 여러 user-level 스레드가 하나의 OS 스레드 위에서 돌아갑니다.- 컨텍스트 스위치(context switching) 속도가 빠릅니다
- 멀티코어를 활용할 수 없습니다
1:1: 1개의 스레드는 1개의 OS 스레드와 일치합니다.- 멀티코어를 제대로 활용할 수 있습니다
- 컨텍스트 스위치 속도가 매우 느립니다
M:N: 여러개의 OS 스레드 위에 여러개의 고루틴을 돌립니다.- 컨텍스트 스위치 속도도 빠르고 멀티코어도 활용할 수 있습니다
- 구현이 어렵습니다
Go의 경우 M:N 모델을 채택함과 동시에 구현이 어렵다는 단점을 언어 차원에서 구현하여 제공함으로 해소시켰습니다.
Go 스케쥴러 내부
Go의 스케쥴러는 G, M, P로 구성되어 돌아가고 있습니다.
G
type g struct {
// Stack parameters.
// stack describes the actual stack memory: [stack.lo, stack.hi).
// stackguard0 is the stack pointer compared in the Go stack growth prologue.
// It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.
// stackguard1 is the stack pointer compared in the C stack growth prologue.
// It is stack.lo+StackGuard on g0 and gsignal stacks.
// It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash).
stack stack // offset known to runtime/cgo
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
stktopsp uintptr // expected sp at top of stack, to check in traceback
param unsafe.Pointer // passed parameter on wakeup
atomicstatus uint32
stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus
goid int64
waitsince int64 // approx time when the g become blocked
waitreason string // if status==Gwaiting
schedlink guintptr
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
paniconfault bool // panic (instead of crash) on unexpected fault address
preemptscan bool // preempted g does scan for gc
gcscandone bool // g has scanned stack; protected by _Gscan bit in status
gcscanvalid bool // false at start of gc cycle, true if G has not run since last scan; TODO: remove?
throwsplit bool // must not split stack
raceignore int8 // ignore race detection events
sysblocktraced bool // StartTrace has emitted EvGoInSyscall about this goroutine
sysexitticks int64 // cputicks when syscall has returned (for tracing)
traceseq uint64 // trace event sequencer
tracelastp puintptr // last P emitted an event for this goroutine
lockedm *m
sig uint32
writebuf []byte
sigcode0 uintptr
sigcode1 uintptr
sigpc uintptr
gopc uintptr // pc of go statement that created this goroutine
startpc uintptr // pc of goroutine function
racectx uintptr
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
cgoCtxt []uintptr // cgo traceback context
labels unsafe.Pointer // profiler labels
timer *timer // cached timer for time.Sleep
selectDone uint32 // are we participating in a select and did someone win the race?
// Per-G GC state
// gcAssistBytes is this G's GC assist credit in terms of
// bytes allocated. If this is positive, then the G has credit
// to allocate gcAssistBytes bytes without assisting. If this
// is negative, then the G must correct this by performing
// scan work. We track this in bytes to make it fast to update
// and check for debt in the malloc hot path. The assist ratio
// determines how this corresponds to scan work debt.
gcAssistBytes int64
}
G는 Goroutines, 고루틴을 의미합니다.
M
type m struct {
g0 *g // goroutine with scheduling stack
morebuf gobuf // gobuf arg to morestack
divmod uint32 // div/mod denominator for arm - known to liblink
// Fields not known to debuggers.
procid uint64 // for debuggers, but offset not hard-coded
gsignal *g // signal-handling g
sigmask sigset // storage for saved signal mask
tls [6]uintptr // thread-local storage (for x86 extern register)
mstartfn func()
curg *g // current running goroutine
caughtsig guintptr // goroutine running during fatal signal
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
id int32
mallocing int32
throwing int32
preemptoff string // if != "", keep curg running on this m
locks int32
softfloat int32
dying int32
profilehz int32
helpgc int32
spinning bool // m is out of work and is actively looking for work
blocked bool // m is blocked on a note
inwb bool // m is executing a write barrier
newSigstack bool // minit on C thread called sigaltstack
printlock int8
incgo bool // m is executing a cgo call
fastrand uint32
ncgocall uint64 // number of cgo calls in total
ncgo int32 // number of cgo calls currently in progress
cgoCallersUse uint32 // if non-zero, cgoCallers in use temporarily
cgoCallers *cgoCallers // cgo traceback if crashing in cgo call
park note
alllink *m // on allm
schedlink muintptr
mcache *mcache
lockedg *g
createstack [32]uintptr // stack that created this thread.
freglo [16]uint32 // d[i] lsb and f[i]
freghi [16]uint32 // d[i] msb and f[i+16]
fflag uint32 // floating point compare flags
locked uint32 // tracking for lockosthread
nextwaitm uintptr // next m waiting for lock
needextram bool
traceback uint8
waitunlockf unsafe.Pointer // todo go func(*g, unsafe.pointer) bool
waitlock unsafe.Pointer
waittraceev byte
waittraceskip int
startingtrace bool
syscalltick uint32
thread uintptr // thread handle
// these are here because they are too large to be on the stack
// of low-level NOSPLIT functions.
libcall libcall
libcallpc uintptr // for cpu profiler
libcallsp uintptr
libcallg guintptr
syscall libcall // stores syscall parameters on windows
mOS
}
M은 Machine, OS의 스레드를 뜻합니다. 표준 POSIX 스레드를 따릅니다.
P
type p struct {
lock mutex
id int32
status uint32 // one of pidle/prunning/...
link puintptr
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
mcache *mcache
racectx uintptr
deferpool [5][]*_defer // pool of available defer structs of different sizes (see panic.go)
deferpoolbuf [5][32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
goidcache uint64
goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
// runnext, if non-nil, is a runnable G that was ready'd by
// the current G and should be run next instead of what's in
// runq if there's time remaining in the running G's time
// slice. It will inherit the time left in the current time
// slice. If a set of goroutines is locked in a
// communicate-and-wait pattern, this schedules that set as a
// unit and eliminates the (potentially large) scheduling
// latency that otherwise arises from adding the ready'd
// goroutines to the end of the run queue.
runnext guintptr
// Available G's (status == Gdead)
gfree *g
gfreecnt int32
sudogcache []*sudog
sudogbuf [128]*sudog
tracebuf traceBufPtr
// traceSweep indicates the sweep events should be traced.
// This is used to defer the sweep start event until a span
// has actually been swept.
traceSweep bool
// traceSwept and traceReclaimed track the number of bytes
// swept and reclaimed by sweeping in the current sweep loop.
traceSwept, traceReclaimed uintptr
palloc persistentAlloc // per-P to avoid mutex
// Per-P GC state
gcAssistTime int64 // Nanoseconds in assistAlloc
gcBgMarkWorker guintptr
gcMarkWorkerMode gcMarkWorkerMode
// gcw is this P's GC work buffer cache. The work buffer is
// filled by write barriers, drained by mutator assists, and
// disposed on certain GC state transitions.
gcw gcWork
runSafePointFn uint32 // if 1, run sched.safePointFn at next safe point
pad [sys.CacheLineSize]byte
}
P는 Processor, 프로세서를 뜻합니다. 정확히 말해서 P는 스케쥴링에 대한 context를 지니고 있습니다.
스케쥴러의 작동 원리
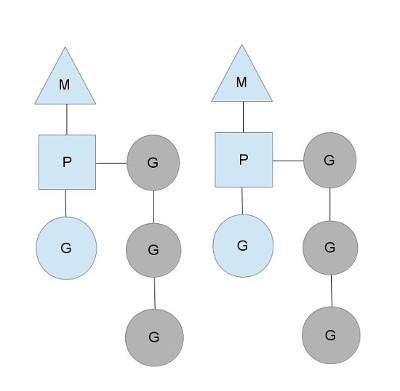
위에서 말했듯 M은 스레드(machine), P는 프로세서(context), G는 고루틴(goroutine)을 의미합니다. context인 P의 갯수는 GOMAXPROCS 환경 변수로 설정이 되는데 Go 런타임에서 runtime.GOMAXPROCS() 함수로 그 갯수가 조절될 수도 있습니다. 대부분 프로그램을 처음 실행할 때에 이 값을 설정하기 때문에 Go 애플리케이션이 돌아가는 도중에 이 값이 바뀔 일은 거의 없죠.
회색으로 나타나는 부분은 아직 실행중이지는 않지만 스케쥴될 준비가 되어있는 고루틴입니다. 회색으로 나타나있는 부분을 runqueues라고 부르는데 이 큐는 앞으로 실행될 고루틴을 쌓아두는 역할을 하고 P(context)에 종속되어 있습니다. 우리는 한 스레드는 한 개의 작업을 할 수 있다는 사실을 알고 있습니다. 이에 따라 Go의 스케쥴러는 runqueues에 앞으로 실행될 고루틴을 순차적(sequential)으로 쌓아두고 이미 실행중인 고루틴이 작업을 마쳤거나(한 번의 statement 실행도 해당) syscall(후술)을 했을 경우에 큐에서 다음 작업을 꺼내 실행하고 새로 추가되는 작업(이미 돌아가고 있는 작업이거나 새로운 고루틴)을 local runqueue의 가장 끝 부분에 추가하게 됩니다.
syscall이 발생했을 때 (blocking)
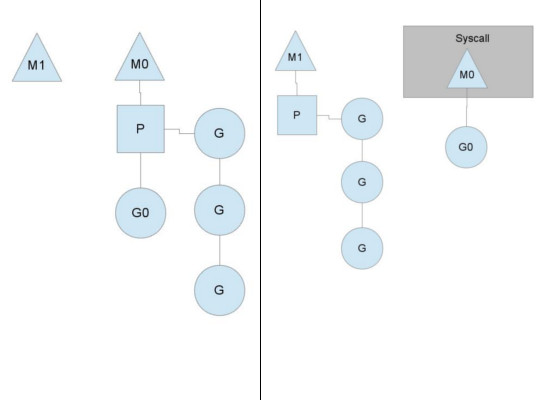
Go 코드를 실행하던 도중 syscall이 발생(주로 I/O)하게 되면 blocking이 발생하게 되는데 이 경우 해당 스레드에 영향을 끼치기 때문에 성능 저하를 불러올 수 있게 됩니다. 따라서 Go의 스케쥴러는 계속해서 멈추지 않고 스케쥴링을 할 수 있도록 syscall이 발생한 고루틴을 다른 스레드로 넘겨(hand off) 모든 고루틴이 정상적으로 작동할 수 있도록 보장합니다. 이후에 syscall 처리가 끝난 고루틴은 잠시 넘겼던 P(context)를 다시 찾아와서 붙게 되거나 global runqueues에 들어가게 됩니다.
이에 대한 글이 Go Google Groups에 올라왔었는데 제목은 왜 고루틴 1000개를 만들었는데 OS 스레드 1000개가 생기나요? 입니다. 앞서 우리는 고루틴은 스레드 위에서 다중화하여 돌아간다고 배웠습니다. 그런데 왜그럴까요? 이 파트에서 설명하는 내용 때문입니다. 위 이미지에서 G0이 돌아가다가 syscall을 만났을 때 이는 다음 고루틴 실행을 지연시킬 수 있으며 스레드 성능에 영향을 끼치게 됩니다. 따라서 Go의 스케쥴러는 syscall이 발생한 고루틴을 독립적으로 처리하도록 하면서 나머지 context는 다른 스레드(위 이미지에서 M1)로 넘기게 됩니다.
이것이 바로 M에 P(context)가 붙는 이유입니다. 실행중인 스레드가 blocking 되었을 때 다른 스레드로 현재 상태(state)를 그대로 넘겨 지속적으로 처리를 할 수 있도록 보장하기 위해 P(context)가 구현되었고 이는 GOMAXPROCS값이 1이더라도 Go가 멀티스레드로 동작하는 이유입니다.
효율적인 스레드 스케쥴링: 고루틴 훔쳐가기
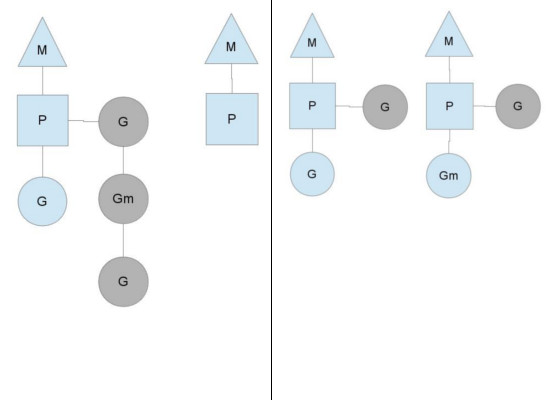
위의 예는 GOMAXPROCS가 2로 설정된 경우입니다. 두 개의 M이 존재하고 왼쪽에 있는 M(편의상 M0이라 부르겠습니다)은 1개의 고루틴을 처리하고 있고 3개의 고루틴을 runqueues에 지니고 있는 상태입니다. 즉 unbalanced 상태에 놓여져 있습니다. 이 상황은 Go 런타임에서 생각보다 자주 등장하게 됩니다. M0이 더 무거운 작업을 처리하고 있다면 이러한 상황이 빈번히 발생하게 되겠죠. (과거 Go에는 global runqueues가 있었지만 lock-release 문제로 P마다 own runqueues를 할당하는 방식으로 변경되었습니다)
위 상황에서 Go 스케쥴러는 가장 우선적으로 global runqueues에 쌓여있는 고루틴을 먼저 가져오려 시도하고 그 후에는 M0에 있는 고루틴 4개의 절반인 2개(Gm과 G)를 M1에 재배치하게 되고 이 상황을 steals(훔쳐가기)라고 표현합니다. 그 결과 절반을 가져가서 Gm을 바로 M1 스레드에서 실행할 수 있게 되고 전반적으로 볼 때 Go는 놀지 않고 많은 작업을 더 효율적으로 동시에 처리할 수 있게 됩니다.
고루틴의 CS 시점
시스템 콜이 발생하면 고루틴의 CS가 이루어진다는 것을 알았습니다. 그러면 정확히 어느 시점에서 고루틴의 CS가 이루어질까요? 고루틴의 CS는 다음 시점에서 이루어집니다:
- unbuffered 채널에 접근할 때(읽거나 쓸 때)
- 시스템 I/O가 발생했을 때
- 메모리가 할당되었을 때
time.Sleep()코드 실행(python asyncio에서asyncio.sleep()을 이용해 yield하는 것과 유사합니다)runtime.Gosched()코드 실행
고루틴과 스레드의 간단한 비교부터 고루틴 내부의 작동 원리(스케쥴링 방식)까지 알아보았습니다. 고루틴은 M:N 스레드 모델로 볼 때 세상에 없던 모델도 아니고 아무도 상상하지 못했던 모델도 아닙니다. 하지만 GIL(Global Interpreter Lock) 또는 여러 이유에서 멀티코어를 제대로 활용하지 못하고 있는 대부분 스크립트 언어와 비교해볼 때 언어 차원에서 다중화(multiplexed)된 스레드 모델을 제공한다는 점은 Go의 가장 큰 장점이면서 오늘날 Go가 이렇게 크게 성장하는데 큰 원동력이 되었습니다.
다음 글에서는 고루틴의 제대로 된 사용 방법과 고루틴에 대한 오해와 진실을 알아보도록 하겠습니다. :)
