이 글은 V8 Javascript Engine 공식 블로그에 올라온 아래 글의 번역글입니다.
Concurrent marking in V8
https://v8project.blogspot.com/2018/06/concurrent-marking.html
원글 자체가 쉬우면서 이따금씩 어려운 설명이 나오기 때문에 오역이 있을 수 있습니다. 댓글 또는 이메일로 수정 피드백 남겨주시면 감사하겠습니다. :)
V8의 지속적인 마킹
이 글에서는 지속적인 마킹(concurrent marking)이라 불리는 가비지 컬렉션(GC) 기술에 대해 설명해보겠습니다. 이 최적화는 GC가 live object를 입에서 찾고 마킹하는 동안 자바스크립트 앱이 멈추지 않고 계속해서 작동할 수 있도록 하는 최적화입니다. 우리가 직접 해본 벤치마크에서 지속적인 마킹은 메인 스레드에서 마킹하는 시간의 60-70% 정도를 줄여주는 결과로 나타났습니다. 지속적인 마킹은 Orinoco project의 마지막 퍼즐조각입니다 — 이 프로젝트는 오래된 가비지 컬렉터를 거의 동시, 그리고 병렬로 작동하는 새로운 가비지 컬렉터로 서서히 교체하는 프로젝트입니다. 지속적인 마킹은 Chrome 64 및 Node.js v10에서 기본적으로 활성화되어 있습니다.
배경
마킹(marking; 식별, 표기)은 V8 Mark-Compact GC의 한 부분(단계)입니다. 이 단계에서 컬렉터는 살아있는 모든 객체를 탐색하고 마킹합니다. 마킹은 글로벌 객체나 현재 활성화되어 있는 함수 등의 알려진 살아있는 객체의 셋으로부터 시작됩니다 — roots라고 불리죠. 컬렉터는 roots를 live 상태로 마킹하고 더 많은 살아있는 객체를 찾아내기 위해 해당 객체들의 포인터를 쫒습니다. 이렇게 컬렉터는 계속해서 새롭게 발견된 객체를 마킹하고 더 이상 마킹할 객체가 없을 때까지 포인터를 쫒아갑니다. 마킹이 끝나면, heap에서 마킹되지 않은 모든 객체는 애플리케이션에서 더이상 접근할 수 없고 안전하게 메모리로 반환될 수 있습니다.
마킹을 graph traversal 과정이라 생각해봅시다. heap에 있는 객체는 모두 그래프의 노드입니다. 다른 객체를 가리키는 한 객체의 포인터는 그래프의 가장자리 부분입니다. 그래프에 노드가 주어지면 우리는 객체의 숨겨진 클래스를 이용하는 해당 노드의 다른 가장자리 부분을 찾을 수 있습니다.
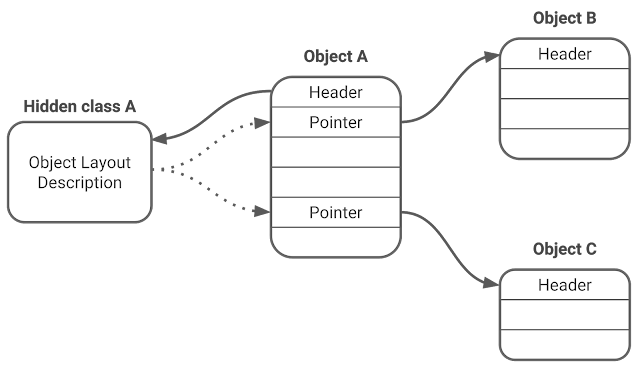
Figure 1. 객체 그래프
V8은 마킹을 두개의 마킹 비트(mark-bits)를 한 객체에 두고 marking worklist를 사용하는 방식으로 구현했습니다. 두개의 마킹 비트(mark-bits)는 다음 세가지 컬러로 나뉩니다: 화이트(00), 그레이(10), 블랙(11). 기본적으로 모든 객체는 화이트(00)입니다, 컬렉터가 아직 발견하지 못했다는 것을 의미하죠. 화이트 객체는 컬렉터가 해당 객체를 발견하고 marking worklist에 넣었을 때 그레이(10) 객체가 됩니다. 그레이 객체는 컬렉터가 마킹 리스트에서 해당 객체를 꺼내고(pop) 해당 객체의 모든 필드를 방문(visits)했을 때 블랙(11) 객체가 됩니다. 이런 스키마를 tri-color 마킹이라 부릅니다. 더이상 그레이 객체가 없다면 마킹은 끝나게 됩니다. 남은 모든 화이트 객체는 접근할 수 없고 안전하게 메모리로 반환될 수 있습니다.

Figure 2. roots에서부터 시작되는 마킹.

Figure 3. 컬렉터가 그레이 객체의 포인터를 프로세싱하여 블랙 객체로 전환하는 모습.

Figure 4. 마킹이 끝난 이후 최종 상태.
한가지 주목해야 할 사실은 위에서 소개한 마킹 알고리즘은 마킹이 작동하는 동안 애플리케이션이 일시중지(pause)된 상태에서만 작동한다는 것입니다. 마킹 도중 애플리케이션이 작동하게 된다면 애플리케이션이 그래프를 바꿀 수 있을 것이고 이는 결국 컬렉터가 모든 살아있는 객체를 소멸시킬 수 있는 위험에 처할 수 있게 됩니다.
마킹에 따른 일시중단(pause) 줄이기
큰 힙에서 한번에 모든 객체를 마킹하게 된다면 몇백 밀리초가 소요됩니다.

이렇게 긴 일시중단은 애플리케이션이 응답하지 않거나 사용자 경험을 나쁘게 만들 수 있습니다. 2011년에 V8은 stop-the-world 마킹(작동중 전체중단)을 incremental 마킹(점진적으로 쌓아뒀다가 한번에 처리)으로 전환했습니다. incremental 마킹동안 가비지 컬렉터는 마킹하는 작업을 세분화하여 여러 조각으로 나눈 후 해당 조각들 사이에서(틈에서) 앱이 돌아갈 수 있도록 했습니다.

가비지 컬렉터는 애플리케이션에서 할당되는 비율에 맞게끔 각 조각에서 incremental 마킹이 얼마나 작동할지를 결정합니다. 일반적인 상황에서 이런 방식은 애플리케이션의 응답성을 엄청 크게 향상시켜 줍니다. 하지만 메모리 부하가 큰 곳에 올라가있는 큰 힙에선 컬렉터가 alloc을 유지하려 함에 따라 여전히 긴 시간의 중단이 발생할 수 있습니다.
incremental 마킹은 공짜가 아닙니다. 애플리케이션은 객체 그래프를 바꿀 수 있는 모든 행동에 대해 가비지 컬렉터에게 알려야만 합니다. V8은 이 알리는 과정을 다익스트라 스타일의 write-barrier를 이용해 구현했습니다. object.field = value와 같은 자바스크립트 코드가 실행되어 쓰기 작업이 끝난 이후 V8은 다음과 같은 write-barrier 코드를 삽입합니다:
// `object.field = value` 이후에 호출됩니다.
write_barrier(object, field_offset, value) {
if (color(object) == black && color(value) == white) {
set_color(value, grey);
marking_worklist.push(value);
}
}
이런 write-barrier는 블랙 객체가 흰색 객체를 가리키지 않도록 강제(보장)합니다. 이런 방식은 강한 불변(invariant) tri-color라 부르기도 하며, 애플리케이션이 가지비 컬렉터로부터 살아있는 객체를 숨기지 못하도록 보장하여 마킹이 끝났을 때 모든 화이트 객체가 확실하게(truly) 애플리케이션에서 접근될 수 없고 안전하게 메모리로 반환될 수 있게끔 합니다.
incremental 마킹은 앞서 작성한 블로그 포스트에서 설명했던 유휴 시간 가비지 컬렉터(idle time garbage collection)와 함께 유연하게 작동합니다. Chrome의 Blink 작업 스케쥴러(task scheduler)는 아무런 문제 없이 메인 스레드에서 유휴 시간동안 작은 incremental 마킹 작업을 스케쥴 할 수 있습니다. 이 최적화는 유휴 시간(idle time)만 있다면 매우 잘 작동합니다.
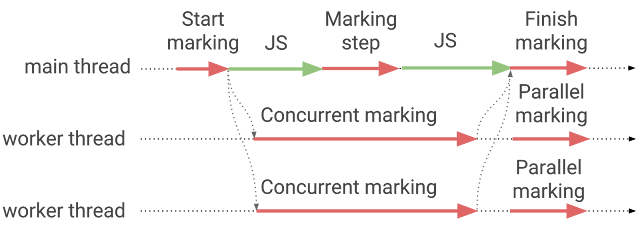
write-barrier 비용(cost)으로 인해 incremental 마킹은 애플리케이션의 스루풋(throughput)을 감소시킬 수도 있습니다. 하지만 워커 스레드를 더 두어 스루풋과 중단 시간 모두 개선할 수 있기도 합니다. 워커 스레드에서 마킹을 하는 방법에는 다음 두가지 방법이 있습니다: 병렬 마킹(parallel marking), 동시 마킹(concurrent marking).
병렬 마킹은 메인 스레드와 워커 스레드에서 발생합니다. 병렬 마킹동안 애플리케이션은 잠시 중단됩니다. 멀티 스레드 버전의 stop-the-world 마킹이라고 볼 수 있죠.
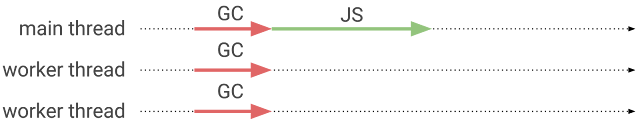
동시 마킹은 대부분 워커 스레드에서 발생합니다. 동시 마킹이 작동중일 때 애플리케이션은 계속해서 작동할 수 있습니다.
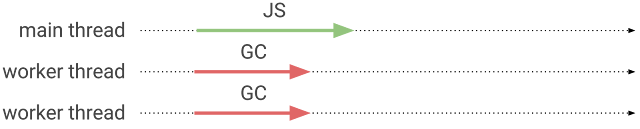
이제 나오는 다음 두 섹션에서 어떻게 우리가 병렬 및 동시 마킹을 V8에 구현했는지에 대해 설명합니다.
병렬 마킹 (parallel marking)
병렬 마킹이 작동하는 동안 우리는 애플리케이션이 같은 시간동안 작동하지 않을 거라고 가정할 수 있습니다. 이런 가정은 (마킹동안)객체 그래프가 변하지 않을 것을 내포하고 있기 때문에 구현을 상당히 쉽게 합니다. 병렬로 객체 그래프를 마킹하기 위해 우리는 우선 가비지 컬렉터 자료구조를 thread-safe하게 만들고 각 스레드간 효율적으로 마킹을 공유할 수 있는 방법을 찾아야 했습니다. 다음 다이어그램은 병렬 마킹과 관련된 자료구조입니다. 화살표는 데이터의 방향을 나타냅니다. 간단하게 설명하기 위해 다이어그램에서 힙 조각모음(heap defragmentation)에 필요한 자료구조는 생략하였습니다.

Figure 5. 병렬 마킹을 위한 자료구조
여기서 알아두어야 할 사실은 각 스레드는 객체 그래프로부터만 읽기만 하고 객체 그래프를 변경하지 않습니다. 객체의 mark-bits와 marking worklist는 읽기 및 쓰기 권한 모두 있어야 합니다.
worklist 마킹하기 및 work 훔치기(stealing)
marking worklist의 구현은 서로 다른 스레드의 작업량을 잘 조율하여 성능 및 밸런스를 조절하는데 매우 중요합니다.
이 교환 공간에서 고려해야 하는 가장 큰 부분은 (a) 모든 객체가 잠재적으로 공유될 수 있다는 부분에 따라 최고의 공유(best sharing)를 위해 완전한 동시성 자료구조 사용 및 (b) 스레드-로컬 스루풋의 최적화를 위해 어떤 객체도 공유할 수 없는 완전히 분리된 스레드-로컬 자료구조 사용입니다. Figure 8은 어떻게 V8이 스레드-로컬 삽입 및 제거를 위한[1] 세그먼트에 기반한 marking worklist를 사용해 이러한 요구에 따른 밸런스를 조절하는지를 보여줍니다. 만약 한 세그먼트가 가득차게 되면, 다른 세그먼트가 가져가서 작업을 처리할 수 있도록 공유된 글로벌 풀에 마킹 작업이 이동(publish and steal)하게 됩니다. 이리하여 V8은, 다른 스레드가 해당 스레드가 가진 로컬 세그먼트를 모두 처리하여 비게되는 동안 한 싱글 스레드가 객체의 새로운 서브 그래프(sub-graph of objects)에 도달한 케이스를 여전히 처리할 수 있다면 마킹 스레드가 어떠한 동기화 작업도 없이 로컬에서 처리할 수 있도록 합니다.

Figure 6. Marking worklist
동시 마킹
동시 마킹은 워커 스레드가 힙에서 객체를 방문(visits; 찾아다니는 여행)하는동안 메인 스레드에서 자바스크립트 코드가 작동할 수 있게끔 합니다. 이런 동작은 데이터 레이스(race condition)가 발생할 수 있는 가능성을 남겨둡니다. 예로, 자바스크립트는 워커 스레드 풀에서 어떤 필드를 읽고있는 도중에 해당 객체 필드에 쓰기 작업을 할 수도 있습니다. 이런 데이터 레이스는 가비지 컬렉터가 살아있는 객체를 반환하거나, 포인터와 원시값(primitive values)을 혼합하는 등, 가비지 컬렉터를 혼란스럽게 할 수 있습니다.
객체 그래프를 변경할 수 있는 메인 스레드에서의 각각의 동작은 데이터 레이스의 가능성을 제공합니다. V8은 많은 객체 레이아웃 최적화가 포함된 고성능 엔진이기 때문에, 데이터 레이스가 발생할 수 있는 근원지의 목록은 더 길 수도 있습니다. 다음은 높은 레벨(high-level)에서의 항목입니다:
- 객체 (메모리)할당 (object allocation)
- 객체 필드 쓰기작업 (write to an object field)
- 객체 레이아웃 변경 (object layout changes)
- 스냅샷으로부터 역직렬화 (deserialization from the snapshot)
- 최적화되지 않은 함수의 처리? (materialization during deoptimization of a function)
- 낮은 세대 GC[2]의 수행 (evacuation during young generation garbage collection)
- 코드 패칭 (code patching)
메인 스레드는 이런 동작에 대해 워커 스레드와 동기화할 필요가 있습니다. 동기화를 하는데 드는 비용과 복잡도는 각 오퍼레이션에 따라 다릅니다. 대부분의 작업은 원자적 메모리 접근(atomic memory accesses)와 함께 가벼운 동기화를 합니다만 몇몇 작업은 객체에 대한 독립적인(exclusive) 접근을 요구합니다. 다음 서브섹션에서 우리는 몇가지 재밌는 케이스를 모아봤습니다.
Writer barrier
객체 필드에 쓰는 작업으로 인해 발생하는 데이터 레이스는 쓰기 작업을 relaxed atomic write[3]으로 전환하고 write barrier를 트윅하는 방식으로 해결될 수 있습니다:
// atomic_relaxed_write(&object.field, value); 이후 실행
write_barrier(object, field_offset, value) {
if (color(value) == white && atomic_color_transition(value, white, grey)) {
marking_worklist.push(value);
}
}
이전에 쓰였던 write barrier 코드와 한번 비교해보세요:
// `object.field = value` 이후 실행
write_barrier(object, field_offset, value) {
if (color(object) == black && color(value) == white) {
set_color(value, grey);
marking_worklist.push(value);
}
}
두가지 변화가 있습니다:
- 소스 객체의 컬러 체크 코드가 사라졌습니다. (
color(object) == black) value의 컬러를 화이트에서 그레이로 전환하는 코드가 원자적(atomically)으로 작동합니다.
소스 객체 컬러 체크 부분을 제외한다면 write barrier는 더 보수적으로(conservative) 작동하게 되었습니다. 예로 위 코드는 실제로 객체가 정말로 도달할 수 없더라 하더라도 살아있는 것으로 마킹할 겁니다. 우리는 쓰기 작업과 write barrier 사이에 많은 비용을 요구로 하는 메모리 fence를 방지하기 위해 체크하는 부분을 제거했습니다:
atomic_relaxed_write(&object.field, value);
memory_fence();
write_barrier(object, field_offset, value);
메모리 fence가 없다면 객체의 컬러를 가져오는 작업은 쓰기작업 전으로 재배치될 수 있습니다. 만약 우리가 재배치를 막지 않는다면 write barrier는 해당 객체를 그레이로 보고 끄집어 낼겁니다(bail out), 워커 스레드가 새로운 값을 확인하지 못하고 객체를 마킹하는동안 말이죠. 다익스트라 등이 제안한 원래 write barrier 또한 객체 색상을 체크하지 않습니다. 간단하게 하기 위해서요, 하지만 우리는 정확하게 작동하기 위해 그것을 할 필요가 있습니다.
Bailout worklist
코드 패칭과 같은 몇몇 작업은 객체에 대한 단독 액세스(exclusive access)를 요구로 합니다. 초기에 우리는 객체별로 락을 거는 것을 피했었습니다, 왜냐하면 우선순위 역전 현상(priority inversion problem)[4]이 생길 수도 있기 때문입니다. 메인 스레드는 객체 락을 쥐고 있는 워커 스레드가 디스케쥴 될때까지 기다려야 하는거죠. 객체에 락을 거는 대신, 우리는 워커 스레드가 직접 객체를 방문하지 않고 처리할 수 있도록 하였습니다. 워커 스레드는 메인 스레드에서만 처리되는 bailout worklist에 객체를 넣음으로서 이를 처리합니다:

Figure 7. The bailout worklist
워커 스레드는 최적화된 코드 객체, 숨겨진 클래스, 그리고 약한 컬렉션(weak collections)을 bailout하도록 합니다, 왜냐하면 이걸 직접 방문(visiting)하게 되면 락을 걸 필요가 생기거나, 복잡한 동기화 프로토콜이 필요해지기 때문입니다.
뒤돌아서 다시보면 bailout worklist는 점진적 개발에 아주 좋은 것으로 판별되었습니다. 우리는 워커 스레드가 모든 객체 타입을 bailout하게끔 구현하기 시작했고 동시성을 차근차근 늘렸습니다.
객체 레이아웃 변동
어떤 객체의 한 필드에는 다음 세가지 값이 들어갈 수 있습니다: 태그된 포인터(a tagged pointer), 태그된 작은 정수형(a tagged small integer, Smi로도 알려짐), 태그되지 않은 값(an untagged value like an unboxed floating-point number). 포인터 태깅[5]은 unboxed integers의 효율적인 표현을 가능하게 해주는 잘 알려진 기술입니다. V8에서 태그된 값의 가장 작은 의미있는 비트(the least significant bit of a tagged value)는 그것이 포인터인지 아니면 integer인지를 나타냅니다. 이는 포인터가 word-aligned라는 사실에 기반합니다. 필드가 tagged인지 아니면 untagged인지에 대한 정보는 객체의 숨겨진 클래스에 저장됩니다.
V8의 몇몇 작업은 객체를 다른 숨겨진 클래스로 변환하는 과정을 통해 객체의 필드를 tagged에서 untagged(또는 그 외)로 변경합니다. 이런 객체 레이아웃 변경은 동시 마킹에 매우 위험합니다. 만약 워커 스레드가 오래된 숨겨진 클래스를 이용해 객체를 동시에 방문하고 있는 도중에 변화가 발생한다면, 두가지 버그가 발생할 수 있습니다. 첫번째로, 워커가 해당 객체가 untagged value인 것으로 생각하고 포인터를 놓칠 수 있습니다. writer barrier는 이러한 버그로부터 보호합니다. 두번째로, 워커가 untagged value를 pointer로 착각하고 레퍼런스를 해제(dereference)할 수도 있습니다, 이렇게 되면 잘못된 메모리 접근으로 보통 프로그램에 크래시가 뒤따르게 됩니다. 이러한 문제를 다루기 위해 우리는 객체의 mark-bit를 동기화하는 스냅샷 프로토콜을 사용합니다. 이 프로토콜은 두가지 파트를 포함합니다: 객체 필드를 tagged에서 untagged로 바꾸는 메인 스레드, 객체를 방문하는 워커 스레드. 필드를 바꾸기 전에, 메인 스레드는 객체가 블랙으로 마크되었음을 보장한 후 나중에 방문할 bailout worklist에 넣습니다:
atomic_color_transition(object, white, grey);
if (atomic_color_transition(object, grey, black)) {
// 이 객체는 bailout worklist가 메인 스레드에서 소모될 때 (처리할 때)
// 다시 방문하게 됩니다.
bailout_worklist.push(object);
}
unsafe_object_layout_change(object);
아래 코드에서 볼 수 있듯, 워커 스레드는 우선 객체의 숨겨진 클래스를 불러와 atomic relaxed load operations을 이용해 숨겨진 클래스에 정의된 객체의 필드에 있는 모든 포인터를 스냅샷합니다. 이후 원자적 비교와 스왑 작업을 통해 객체를 블랙으로 마킹하도록 시도합니다. 만약 마킹에 성공한다면 이것이 의미하는 것은 스냅샷이 반드시 숨겨진 클래스와 일관성을 유지해야 한다는 것입니다, 왜냐하면 메인 스레드가 레이아웃을 바꾸기 전에 객체를 블랙으로 마킹하게 될테니까요.
snapshot = [];
hidden_class = atomic_relaxed_load(&object.hidden_class);
for (field_offset in pointer_field_offsets(hidden_class)) {
pointer = atomic_relaxed_load(object + field_offset);
snapshot.add(field_offset, pointer);
}
if (atomic_color_transition(object, grey, black)) {
visit_pointers(snapshot);
}
여기서 알아야 할 점은 안전하지 않은 레이아웃 변화에 영향을 받은 화이트 객체는 메인 스레드에서 마킹되어야 한다는 것입니다. 안전하지 않은 레이아웃 변화는 매우 드문 현상입니다, 따라서 실제 상황에서 성능에 그리 큰 영향을 끼치지는 않습니다.
종합
우리는 동시 마킹을 이미 존재하는 점진적 마킹 구조에 포함시켰습니다. 메인 스레드는 roots를 싹 훑어보고 marking worklist를 채움으로서 마킹을 준비하게 됩니다. 이후 메인 스레드는 동시 마킹 작업을 워커 스레드에 맡깁니다. 워커 스레드는 메인 스레드를 도와 서로 협력하여 marking worklist를 빠르게 처리하게끔 합니다. 가끔 메인 스레드는 bailout worklist와 marking worklist를 처리하여 마킹에 참여하게 됩니다. marking worklist가 비게 되는 때에 메인 스레드는 가비지 컬렉션을 끝내게 됩니다. 완료 시점에 메인 스레드는 roots를 다시 탐색하여 더 많은 화이트 객체를 발견하게 될 수도 있습니다. 이 객체들은 다른 워커 스레드의 도움과 함께 병렬로 마크됩니다.
결과
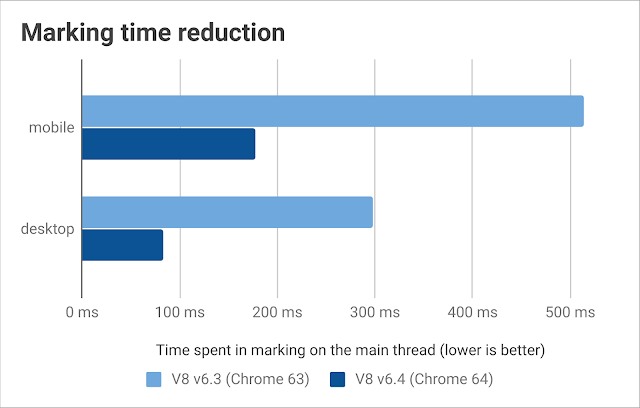
우리의 실제 환경 벤치마크 프레임워크로 테스트해본 결과, 모바일 및 데스크탑 환경 모두에서 한 가비지 컬렉션 사이클마다 메인 스레드 마킹 시간이 65%에서 70% 줄어든 것을 확인할 수 있었습니다.
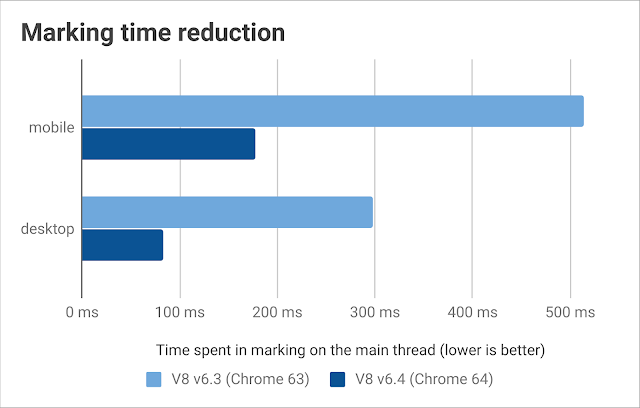
동시 마킹 또한 Node.js에서의 가비지 컬렉션으로 인한 영향을 줄였습니다. 이게 Node.js에서는 특별이 중요한 부분인데 왜냐하면 Node.js는 유휴 시간 가비지 컬렉션 스케쥴링(idle time garbage collection scheduling)이 구현되어있지 않으며 따라서 마킹 시간을 줄일 틈이 없었기 때문입니다. 동시 마킹은 Node.js v10에서 제공됩니다.
Posted by Ulan Degenbaev, Michael Lippautz, and Hannes Payer — main thread liberators
